
Modern software cannot exist without a search and analytics feature. The data is coming from various sources, and the application must be scalable and capable enough to handle a large amount of data in near real-time. It is where Elasticsearch comes in. It is often referred to as a big data solution, analytics database, or as a search engine, which can make you bit confused. But in reality, it is all of these and more! This article will help you understand what is Elasticsearch, how it works, and why is it beneficial for your company. Let's get into it.
What is Elasticsearch?
Elasticsearch is a lightning-fast, scalable full-text search engine. Developed with java and built on top of Lucene, it has easy integrations with the most popular languages. Data is stored in schema-less JSON and uses extensive REST APIs for storing and searching. Although one can use Elasticsearch as the main database, it is not a replacement of relational databases such as MySQL. It is common to be used alongside relational database and inject only searchable data into Elasticsearch.
Main features of Elasticsearch
- Can conduct a lightning-fast full-text search
- Combines different types of searches: structured, unstructured, geolocations, IP, metrics, logging
- Can scale an enormous amount of data
- Is easy to learn and integrate
- Can be combined with machine learning
- Is compatible with REST API and JSON
- Is great for aggregation
- Can provide real-time visualization of data
- Analytics and logging
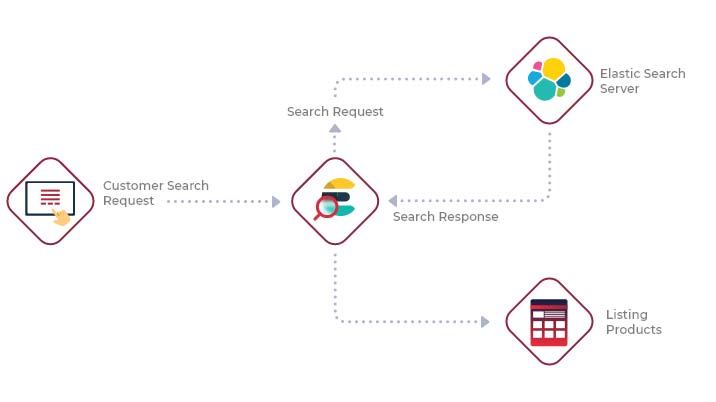
What does Elasticsearch do?
Elasticsearch takes unstructured data from various locations. It stores and indexes this data according to user-specific mapping and makes it easily searchable for the user. As a result, you can use it to store, search and analyze data quickly in almost real-time and get back answers in milliseconds.
While you can use Elasticsearch for full-text searches such as email, document, product search and others alike, it also allows you to store data that needs slicing, dicing and grouping by various dimensions. Such analytical use cases might include metrics, traces, logs, and other time-series data.
As Elasticsearch is a fast and scalable option that can index different types of content, you can use it for various use cases. Application and website search, enterprise search, security and business analytics, geospatial data analysis and visualization are some of them to name. It is a powerful engine that can enhance your search and analytics experience.
Understanding Elasticsearch components
To understand Elasticsearch better, let's take a look at the Elasticsearch components and Elastic stack.
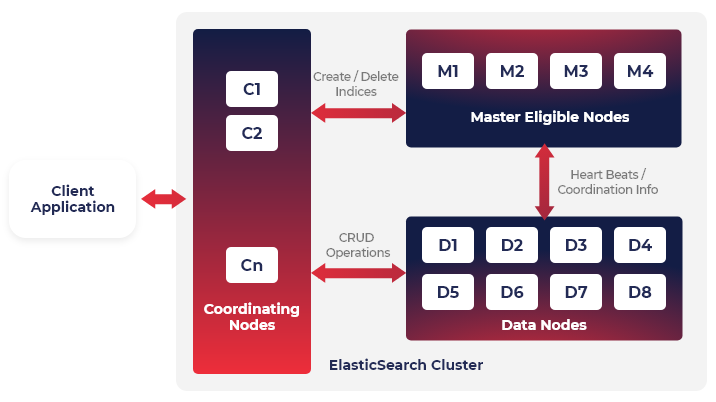
Cluster
Cluster is a collection of connected nodes (servers). The primary purpose of it is to distribute the data across the available nodes evenly. If you have a single node, you have a cluster of one node.
Node
Node is a single physical of a virtual machine. It holds part of the data and provides computing power for indexing and searching. Node is responsible for performing operations such as storing, searching, and indexing. It also maintains the health of the cluster. There are different types of nodes, that differ from each other, based on their responsibilities.
Data Node
Data nodes hold part of the data. They perform data-related operations such as search, CRUD, and aggregations.
Master Node
The purpose of the master node is to perform an administrative task such as making sure all data nodes are available and working or creating indices (database in RDBMS). The master node is a critical part of Elasticsearch. Elasticsearch has the option to have multiple master-eligible nodes.
It is crucial to have at least three master nodes. The default configuration is that all nodes are data nodes as well as master nodes. Although some nodes must be master-eligible through specific configuration, you should also check your default one for corresponding Elasticsearch version.
Coordinating node
The purpose of the coordinating node is to handle user request and distribute it to data or master nodes. Every node does its magic and returns results to the coordinating node, which, sequentially returns a single global result. Every node without role is coordinating node.
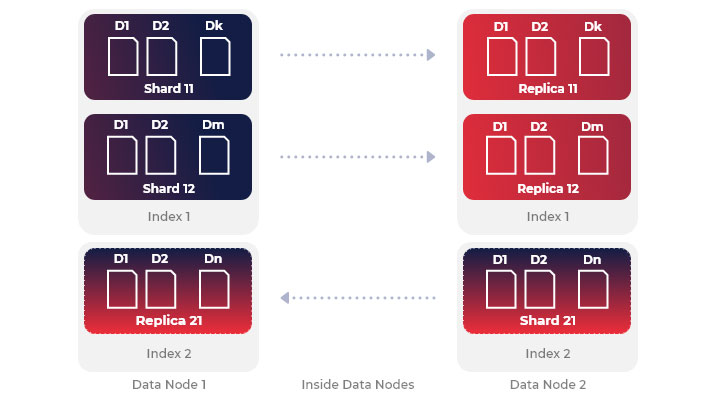
Shards
Elasticsearch indexes (database in RDMBS) are split into shards. You can split Shards of the same index into the same or different nodes. It is important to note, that you should specify shards at the same time of index creation. There are two types of shards replica and primary. Replicas are created on a different node in case of hardware malfunction, and they can also contribute to searching.
Data types
Elasticsearch has a wide variety of data types: Simple data, special, and complex data. Simple data includes text, keyword, numeric data. Special ones are Geo shape and Geo Pint, while in complex ones we mean object and nested.
Elasticsearch Stack (ELK)
Elastic Stack is a set of open-source tools that are used for data ingestion, enrichment, storage, analysis and visualization. The name ELK comes from the three components of Elastic Stack: Elasticsearch, Logstash, and Kibana. (However, now ELK includes Beats as well). Elasticsearch is the central component of ELK. We have already discussed its components and usability. Now let's take a look at Logstash and Kibana.
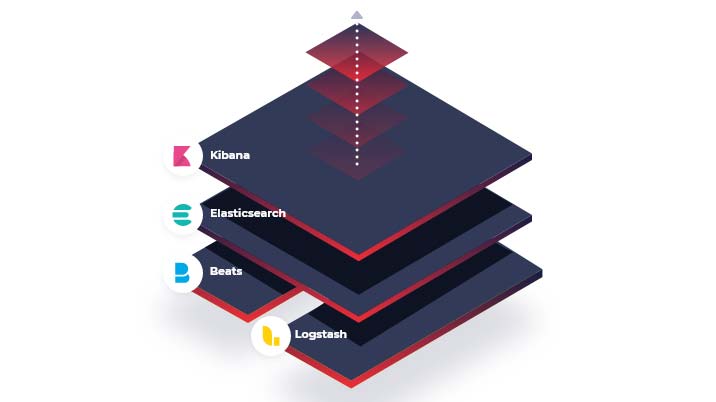
Kibana
Kibana is a tool for data visualization and management. It allows you to visualize real-time data and communicate with Elasticsearch through the graphical interface. You can use it for:
- Searching, viewing and visualizing Elasticsearch data with the help of charts, tables, maps, etc
- Monitoring, managing and securing Elasticsearch instance through the Kibana interface
- Centralized access for build-in solutions for enterprise search applications, observability, and security.
Logstash
Logstash is a server-side data processing pipeline. It allows you to ingest data from multiple sources at the same time, transform it and store it in Elasticsearch. One of the main assets of Logstash is that it can transform and prepare data regardless of its format. It is especially helpful as often data is retrieved from different sources in various formats. Logstash allows you to tie different systems together and publish data, wherever it needs to go.
Why should you use Elasticsearch?
Powerful full-text search engine
Elasticsearch is the most powerful full-text search engine for the large volumes of data. Since it is built on top of Lucene, it has powerful search capabilities and allows you to perform, as well as combine different types of searches.
Fast performance
As Elasticsearch uses distributed inverted indices, it performs search quickly and finds the matches from large data sets.
Operational logging analytics
You can analyze logs by processing billions of events every day to ensure consistent system performance and detect anomalies. It will allow you to improve the customer experience and hence, help your business thrive.
Supported languages
Elasticsearch supports various programming languages including Java, JavaScript (Node.js), Go, .NET (C#), Perl, PHP, Phyton, Ruby.
Scalability
Scalability of Elasticsearch makes it easy to manage the huge amount of data. Because of its distributed architecture, Elasticsearch enables users to scale up to multiple servers and accommodate petabytes of data. We do not need to manually merge the complexity of the distributed design, since Elasticsearch does it automatically.



